

In this blog post, I will summarize my graduation thesis project, which focused on designing and implementing a centralized data-access API for distributed geophysical data sources at the Istituto Nazionale di Geofisica e Vulcanologia (INGV). The project aimed to address the challenges of fragmented data access, high latency, and lack of unified access control in the existing systems.
Problem Statement #
Data collection at the Etna Observatory is extensive but heavily fragmented across independent servers and teams with no shared access layer. The most critical issue discovered during analysis was the Sequential Query Trap: to retrieve a single timeseries dataset, callers had to make multiple chained, sequential requests to legacy PHP systems just to discover what data even existed — traversing a rigid hierarchy of networks, stations, sensors, and signal types before a single data point could be fetched. This caused high network overhead, extreme latency, and maintenance bottlenecks, ultimately blocking the development of unified early-warning systems.
Beyond latency, there was no unified access control layer. External academic partners like the University of Padua could not be safely given access to any subset of the data without exposing entire backend systems. Researchers had to understand the unique quirks of each upstream system — legacy PHP APIs, modern Docker-based REST services, raw file directories, and SQL earthquake catalogs — just to do their work.
The Objective #
To solve this fragmentation, the project focused on designing and implementing a centralized REST API gateway. This API serves as a single entry point for all clients, abstracting away the extreme heterogeneity of the underlying datasources. Rather than embedding resource hierarchies into the URL path (forcing callers to traverse /nets/1/nodes/5/channels/12), the gateway exposes a flat, query-based interface: the path defines the data domain and action, while standard query parameters act as filters. The goal was sub-100 ms response times, strict access control, and the ability to onboard new datasources without touching Go source code.
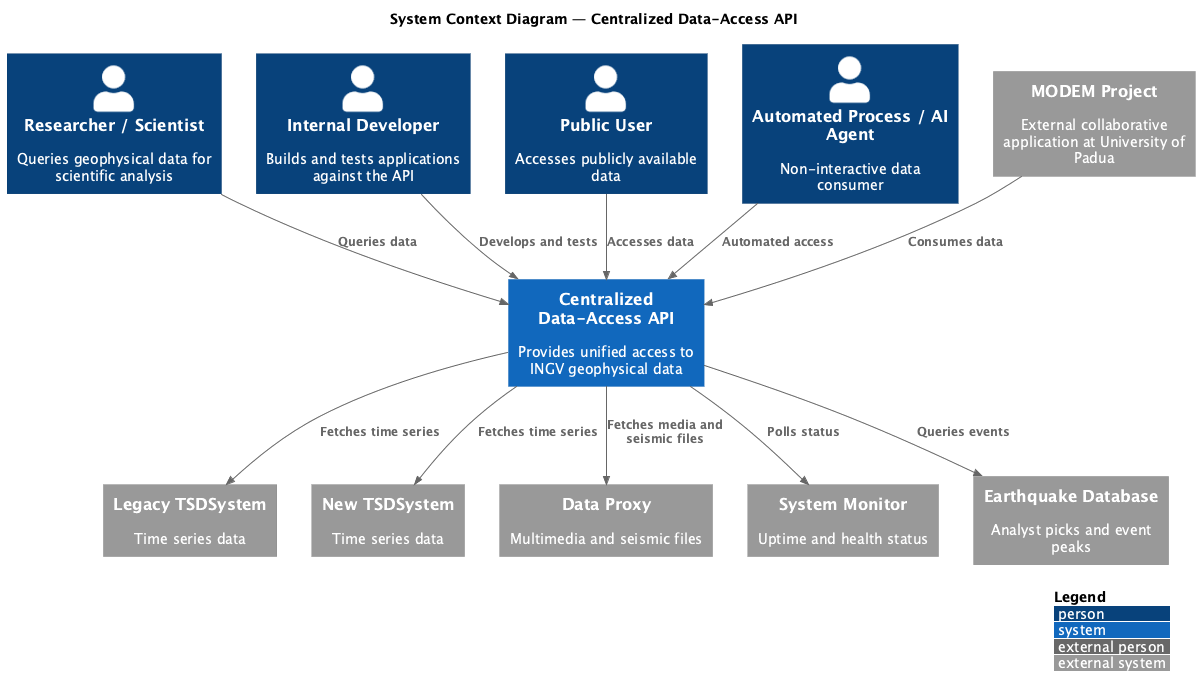
Architectural Approach #
The system architecture was designed around strict decoupling to ensure long-term maintainability. Rather than tightly coupling the API Gateway to specific, shifting database columns, the system employs a Unified Envelope with an Opaque Payload architecture. Three patterns govern the design.
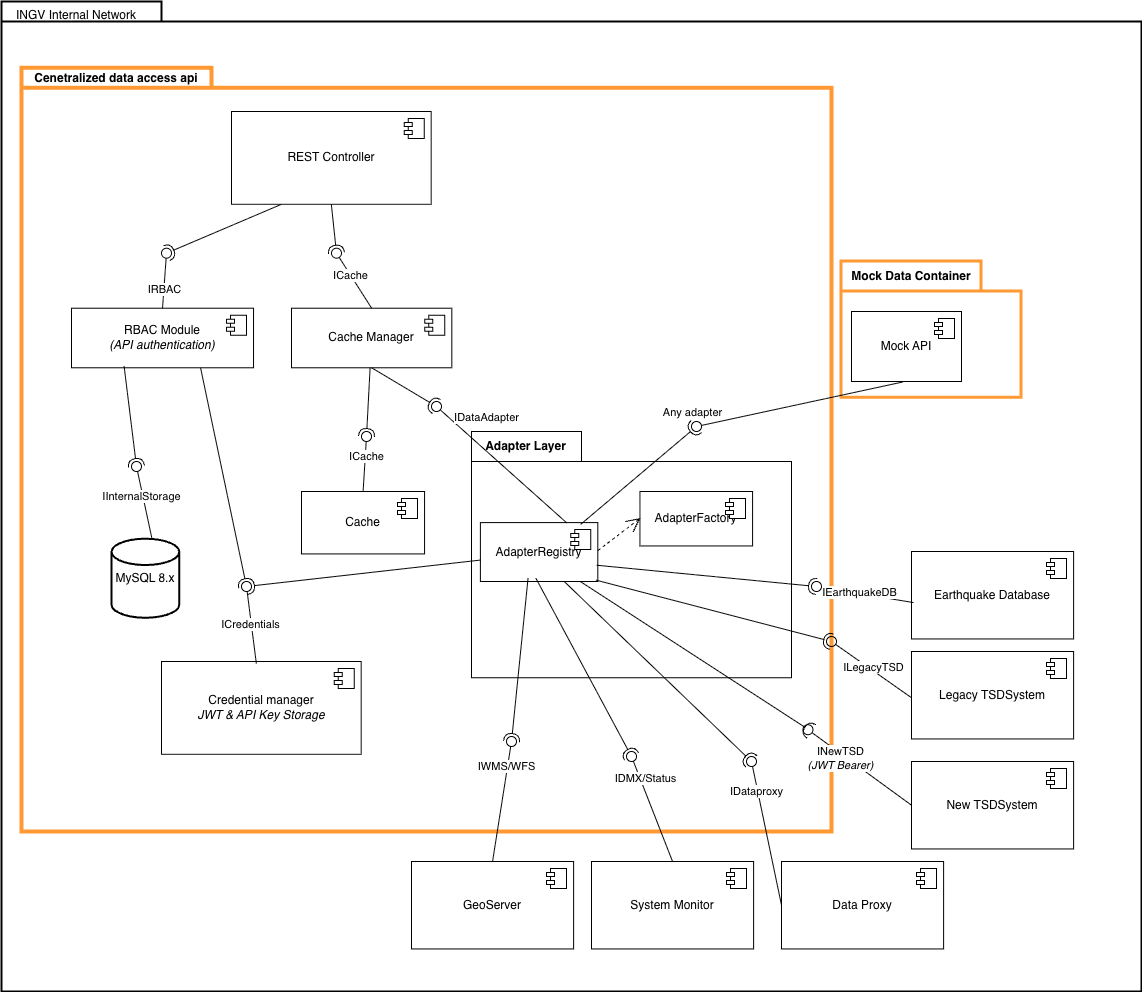
The Facade Pattern: The gateway presents a flat, consistent RESTful interface to researchers. Clients remain entirely agnostic of whether they are querying a 20-year-old columnar database or a modern REST API. Every response — success or failure — is returned in a standardized JSON envelope containing a success flag, a dataType discriminator (collection, timeseries, object, or status), the source adapter that served the request, a data payload, and a meta.query block that explicitly echoes any security filters the gateway injected on the caller’s behalf. This last detail is deliberate: a researcher can inspect meta.query.net_id and see exactly which networks their clearance granted them access to.
Configuration-Driven Adapter Pattern: Upstream datasources are mapped using a dynamic TOML configuration file, removing the need to hardcode routing logic into the Go source code. Each TOML file defines the upstream connection, the API endpoints exposed to consumers, strict parameter contracts, a template string for URL path interpolation or SQL binding, per-endpoint bucket cache granularity, and the role whitelist governing access. When a request arrives, the gateway validates the parameters against the TOML spec, performs string substitution on the template (replacing {{netId}} in HTTP backends or :date_from in SQL backends), injects any required downstream credentials, and executes the call. Adding a new datasource requires only a new TOML file — no recompilation, no restart. A directory watcher hot-reloads configurations at runtime.
Layered Architecture: To prevent security and data-transformation logic from intermingling, the system enforces a strict three-tier internal flow. The Middleware layer handles API key validation and user-attribute lookup. The Orchestration layer manages the AdapterRegistry and coordinates the full request lifecycle. The Translation layer (the adapters themselves) performs template resolution and maps upstream responses to the unified envelope.
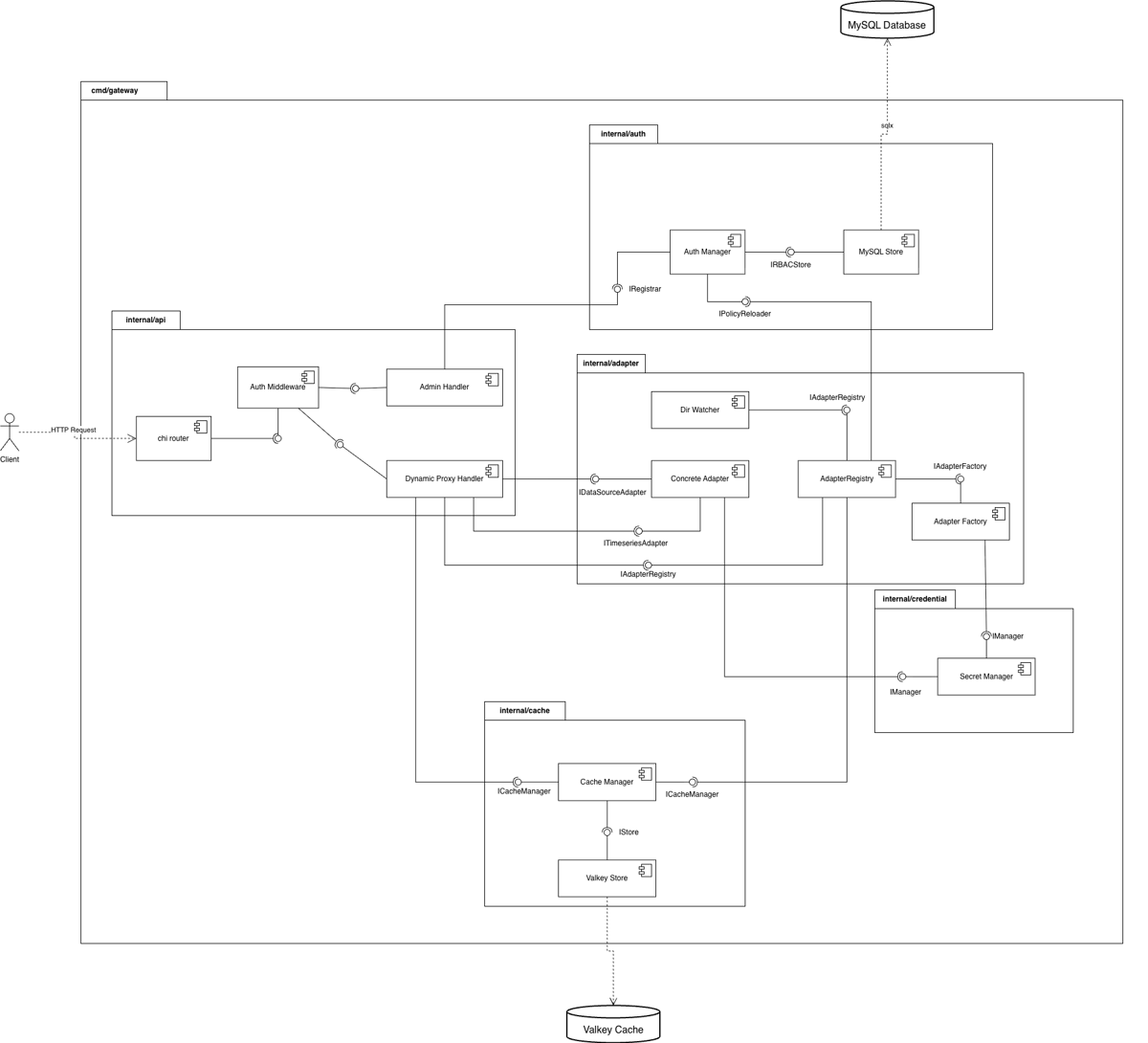
Technology Stack #
Technology selection was predicated on architectural integrity and operational simplicity in a research environment. Each choice came with deliberate rejections.
Golang: Go was chosen primarily for its implicit interface realization (structural typing), which enables a pure implementation of the Dependency Inversion Principle — adapters satisfy the gateway’s IDataSourceAdapter contract implicitly, with no inheritance hierarchy. Go also compiles to a single static binary with no runtime dependencies, allowing a FROM scratch Docker image with sub-one-second startup times. A rejected alternative was C#/.NET: while technically capable, ASP.NET Core’s framework conventions — attribute routing, model binding, a DI container — risk obscuring the AdapterRegistry and layered security pipeline, which are the primary architectural contributions of this design. Go’s explicit error returns also make upstream failure mapping (502s, timeouts, malformed responses) visible at every call site, rather than relying on framework exception handlers that can swallow classification logic.
Valkey: A high-performance, Redis-compatible in-memory store. Valkey was specifically chosen over Redis to avoid vendor lock-in after Redis changed its licensing model to be more restrictive for commercial use. As a Linux Foundation project, Valkey provides identical enterprise-grade capabilities with no future licensing risk for a public-sector organization. Key Go libraries used: go-redis/redis/v9 for Valkey, BurntSushi/toml for configuration parsing, go-sql-driver/mysql for the database, and the stdlib net/http for both the REST controller and upstream HTTP clients.
MySQL 9.x: Serves as the relational database for user permissions and identity management, acting as the single source of truth for RBAC roles and user-network assignments.
Docker: The entire infrastructure is containerized using a multi-stage compilation strategy. The Golang binary is compiled in a builder stage and copied into a minimal final image, keeping deployment artifacts small.
Security Model (Hybrid RBAC / ABAC) #
The gateway uses a defense-in-depth two-tier security model with an automated synchronization process to keep permissions current.
Role-Based Access Control (RBAC) enforces path-level authorization using a deny-by-default whitelist model: a role has access to a datasource path only if it is explicitly listed in that datasource’s TOML [roles.*] block. Five roles are defined. PUBLIC_USER can reach only /discovery endpoints on publicly designated datasources. RESEARCHER — the primary consumer role, covering both internal INGV staff and external collaborators like the MODEM project at UniPD — can access discovery, timeseries, waveforms, and earthquake endpoints, with all responses network-scoped via ABAC. DEVELOPER is intentionally excluded from all datasource-specific paths and works exclusively against the mock container and admin endpoints, keeping their activity fully decoupled from live observatory systems. ADMINISTRATOR holds full access including /admin/* routes for user management and cache invalidation. AUTOMATED_PROCESS mirrors RESEARCHER permissions but uses dedicated service-account API keys rather than user credentials.
Attribute-Based Access Control (ABAC) implements row-level data isolation by automatically injecting allowed_network_ids into upstream queries, preventing horizontal privilege escalation without requiring complex upstream database views. On discovery endpoints where no net_id is supplied by the caller, the ABAC module injects the user’s cleared network IDs from the user_networks MySQL table. If a caller supplies a net_id they are not cleared for, a 403 Forbidden is returned before the adapter is ever called. On timeseries endpoints, no injection occurs — the caller must supply a net_id, and it is validated against their clearance list.
The Sync Worker (Nightly Sweep): A background CRON job runs nightly at 02:00 UTC to synchronize external user permissions with the upstream New TSDSystem. This ensures the gateway’s local ABAC tables are always aligned with the observatory’s latest security clearances. If the upstream call fails, the worker logs the failure and retries on the next cycle rather than rolling back existing permissions — stale-but-valid permissions are safer than an accidental revocation caused by a transient outage. The sync can also be triggered on-demand via POST /admin/users when a new user is provisioned.
Caching and Performance #
A Valkey-based caching layer sits between the security module and the adapter layer. This position is deliberate: the cache is always post-authorization, meaning a cache hit for one user is never served to a user without the appropriate role, and only fully validated requests can consume cache memory (preventing unauthenticated cache exhaustion). The cache uses a Least Frequently Used (LFU) eviction policy rather than the standard LRU, because INGV data access patterns are significantly skewed — certain datasets are queried orders of magnitude more often than others, and LFU keeps “hot” data resident in memory even when rare exploratory queries arrive in bursts.
Timeseries Bucket Caching: Simple key-value caching cannot efficiently serve overlapping time ranges. Two researchers querying different but overlapping windows for the same sensor would both miss the cache even when most data is already stored. To solve this, timeseries responses are split into fixed clock-aligned buckets (minutes, hours, or days depending on the endpoint) before caching. CacheManager.GetRange() resolves a request into its constituent buckets, returns any that are already cached, and fetches only the missing buckets from the upstream adapter. The full response is then assembled from cached and freshly fetched data. If the number of cache misses exceeds a threshold, a single full upstream request is made instead, since the overhead of many small requests can exceed the latency of one larger one.
The cache key for timeseries endpoints encodes all parameters that affect the response — aggregateFunction, groupBySeconds, minThreshold, maxThreshold, gainValue, offsetValue, and the bucket boundary — ensuring that a MAX aggregation and an AVG aggregation for the same sensor never share a cache entry. Discovery endpoints benefit most from caching since they carry no query parameters and their underlying data changes infrequently.
Binary streams (miniSEED, DMX, AVI) bypass the bucket logic and are not cached. The admin endpoint DELETE /admin/cache triggers a full flush via CacheManager.FlushAll(), intended for use after sensor recalibrations or earthquake catalog corrections.

Performance Validation: During a constant-load stress test simulating 50 concurrent virtual users, the gateway achieved a p95 response time of 77.96 ms, comfortably within the strict 100 ms latency requirement.
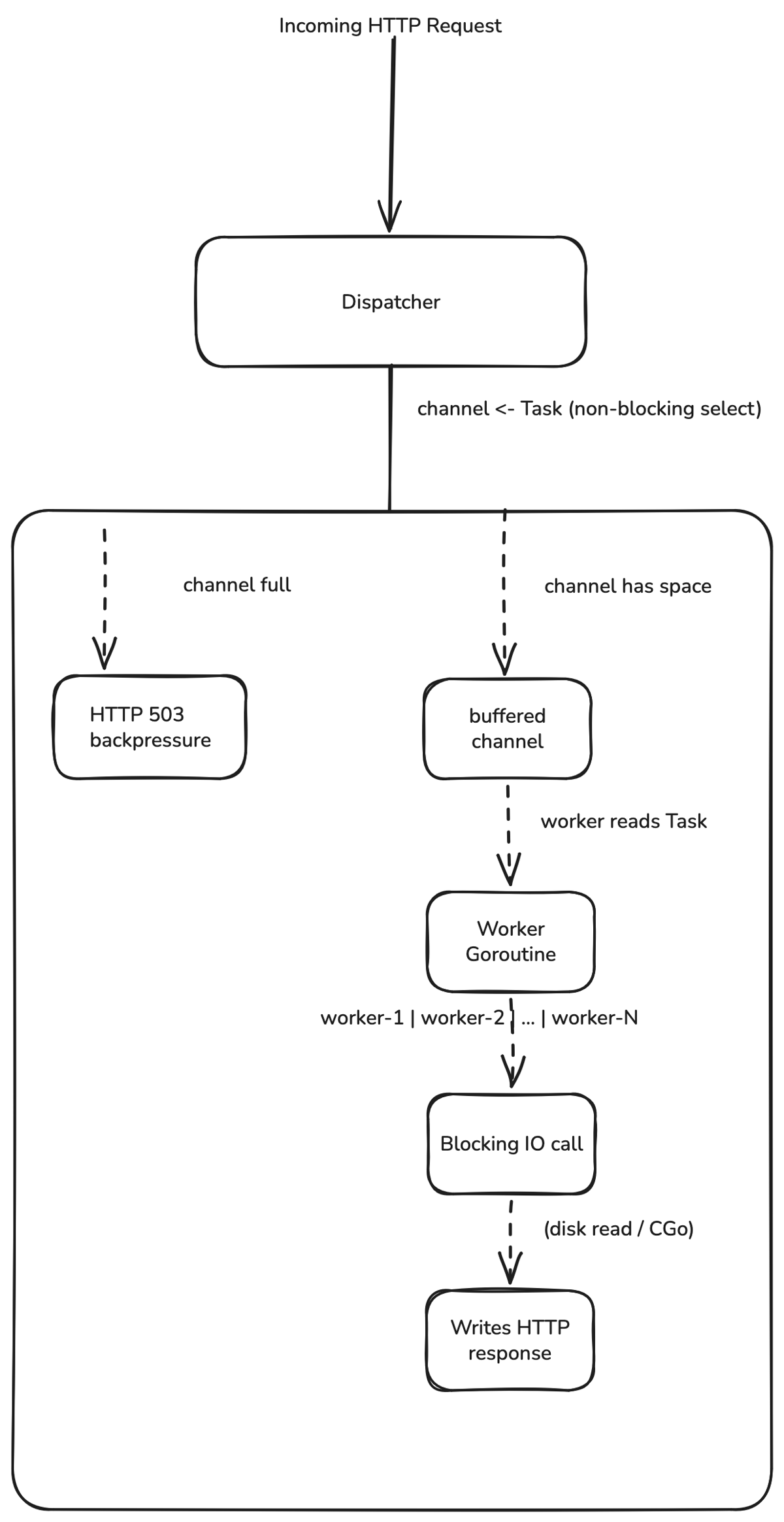
Future-Proofing — Bounded Worker Pool: The Go netpoller offloads network-wait states to the kernel via epoll, handling the current network-bound workload efficiently. However, if future adapters introduce blocking system calls (e.g., direct disk I/O, CGo bindings), the runtime degrades toward a 1:1 goroutine-to-thread mapping, risking Go’s hardcoded 10,000 OS thread limit. A contingency architecture using a Producer-Consumer bounded worker pool has been documented: a fixed fleet of workers (100–500, configurable) consumes tasks from a buffered channel, returning 503 Service Unavailable immediately when the queue is saturated rather than accumulating goroutines in memory. This approach also makes the worker pool depth an exportable metric for Prometheus alerts.
Safe Testing Environment #
The testing strategy uses three deliberate tiers rather than a flat end-to-end approach, because the system’s correctness depends on failure modes that are best caught at different levels of isolation.
Unit Tests target adapter template resolution, cache key generation, and RBAC/ABAC enforcement in complete isolation — no network calls, no database connections. A mistranslated URL template or an incorrect cache key does not cause a crash; it silently returns wrong data, which is why these are caught at the unit level. Key scenarios include asserting that a MAX aggregation and an AVG aggregation for the same sensor produce different cache keys, that a user with no network assignments receives an empty filter causing discovery to return no results, and that missing template parameters produce typed errors rather than malformed upstream requests.
Integration Tests exercise the full request pipeline from the REST Controller through the RBAC module, cache layer, and upstream adapter using a standalone Mock Data Container. The mock uses a flat pattern-matching strategy: all dynamic IDs (UUIDs, timestamps) are stripped from incoming paths and matched to static snapshot files (e.g., /nets/7/nodes/ffcaaa00/channels/2187/query normalizes to /nets/nodes/channels/query → query.json). Switching between mock and production modes requires only editing the baseUrl in the TOML config; the directory watcher picks up the change without a restart, which also tests the hot-reload logic itself. The entire mock suite runs in an air-gapped Docker network with no outbound calls to .int.ingv.it addresses.
Security Tests assert on what does not happen: that an upstream adapter is never called when a user lacks clearance, that the cache is never consulted for an unauthenticated request, and that a PUBLIC_USER role never reaches a RESEARCHER-only path. These are kept deliberately separate from integration tests to prevent passing business logic from masking security failures.
Real-World Integration: The MODEM Project #
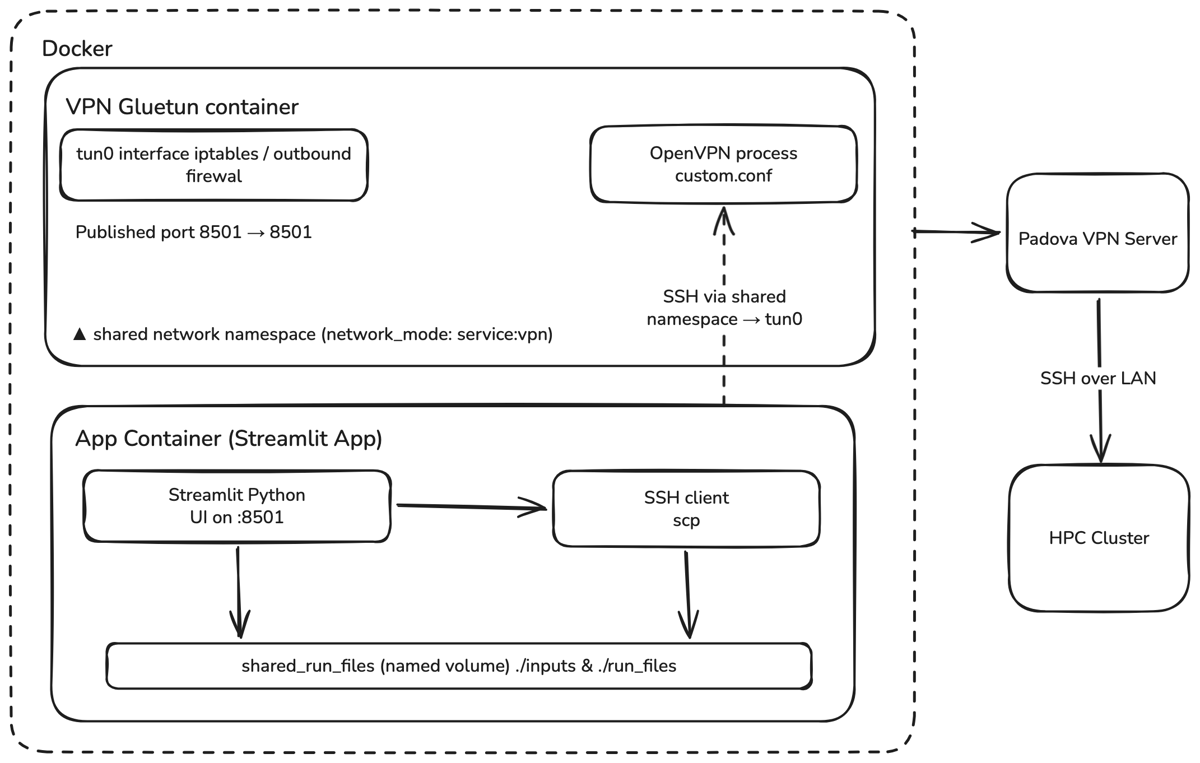
The real-world applicability of the gateway was validated through integration with the MODEM project at the University of Padua. The integration uses a containerized Streamlit application that securely queries the API Gateway over an OpenVPN tunnel within the INGV internal network. Researchers can interactively select datasets, fetch standardized JSON responses, and securely synchronize them with High-Performance Computing (HPC) clusters for 4D Seismic Imaging simulation of the Etna volcano. The gateway’s meta.query block in each response lets the Streamlit pipeline programmatically verify which data domains were accessed — a feature that emerged directly from the AUTOMATED_PROCESS stakeholder requirement for predictable, auditable non-interactive consumption.
Conclusion #
The delivered product is a production-ready API Gateway that successfully unifies fragmented geophysical data sources. By abstracting legacy systems behind a configuration-driven adapter layer, implementing bucket-based caching with LFU eviction, and enforcing a hybrid RBAC/ABAC security model with automated nightly synchronization, the project has established a scalable foundation for the INGV Etna Observatory’s future research and early-warning systems. The system is fully extensible without code changes, validated against a strict 100 ms latency SLA, and safely testable through an air-gapped mock environment that mirrors production behavior down to the adapter translation logic.